Goでの文字列バリデーション
はじめに
これは Kyash Advent Calendar 2022 の4日目の記事です。
Kyashでサーバーサイドエンジニアをやってる omotani( twitter:@k_omotani ) です!
Kyashでは銀行接続やカード登録などで氏名を利用する際に半角 or 全角、ひらがな or カタカナなど特定の文字列か否かのバリデーションを行うことが多くあります。 例えばコンビニチャージと銀行口座登録では相手先が許容する文字が異なったりするので、バリデーションの実装が都度必要になります。 Emailアドレスなどの特定パターンのバリデーションとして正規表現を用いたチェックを行うパターンも多いですが、今回は特定文字種を含んでいるかをチェックする実装としてunicode packageのRangeTableとx/text/width packageを利用したのではまりどころを含めてご紹介したいと思います!
RangeTable
Goのunicode packageのunicode.Inを用いることで文字列のチェックを行うことができます。
import "unicode" func HaveNotHiragana(str string) bool { for _, r := range []rune(str) { if !unicode.In(r, unicode.Hiragana) { return true } } return false }
unicode.Inの第二引数はunicode.RangeTableです。RangeTableはUnicodeの範囲(16bitはunicode.Range16, 32bitはunicode.Range32)を配列として定義することができます。
標準packageとしてunicode.Katakanaなど各言語の標準的なRangeTableが定義済みです。
https://pkg.go.dev/unicode#pkg-variables
例えばKatakanaでは以下のような定義になっています。
var _Katakana = &RangeTable{ R16: []Range16{ {0x30a1, 0x30fa, 1}, {0x30fd, 0x30ff, 1}, {0x31f0, 0x31ff, 1}, {0x32d0, 0x32fe, 1}, {0x3300, 0x3357, 1}, {0xff66, 0xff6f, 1}, {0xff71, 0xff9d, 1}, }, R32: []Range32{ {0x1b000, 0x1b164, 356}, {0x1b165, 0x1b167, 1}, }, }
しかし、unicode.Hiragana “ゐ”や”ゟ”が含まれていたり、unicode.Katakana には㌖などが含まれています。一般的な「カタカナに絞る」みたいなユースケースでは使えないことの方が多いと思います。
その際は自分でRangeTableを定義することで柔軟に対応できます。
例えば全角カタカナor全角アルファベットのみの場合
var kanaRange = &unicode.RangeTable{ R16: []unicode.Range16{ {0x30a1, 0x30f4, 1}, // ァ-ヴ {0x30fc, 0x30fc, 1}, // ー {0xff21, 0xff3a, 1}, // A-Z {0xff41, 0xff5a, 1}, // a-z }, }
のように定義することでunicode.Inと組み合わせ文字種とチェックが行えます。
はまりどころ
基本的にシンプルに利用できるのですが、RangeTableを自分で定義する際に一点はまりどころがありましたので紹介します。(documentをちゃんと読んでなかっただけですが)。
例えば上記の「全角カタカナor全角アルファベットのみ」を以下のように定義すると想定通りには動きません。なぜでしょう?
[]unicode.Range16{
{0x30fc, 0x30fc, 1}, // ー
{0x30a1, 0x30f4, 1}, // ァ-ヴ
{0xff21, 0xff3a, 1}, // A-Z
{0xff41, 0xff5a, 1}, // a-z
},
RangeTableのdocumentに " The two slices must be in sorted order and non-overlapping. ” と書いてあるように、sliceがソートされていないと想定の挙動になりません。
エラーが発生するわけではなく挙動がおかしくなるだけなので、RangeTableを定義する場合にはテストをきちんと書くように気をつけましょう。
golang.org/x/text/width
文字の全角半角は golang.org/x/text/width package で判断できます。
width.LookupRuneによりwidth.Propertiesが取得でき、そこに対してKindを取ることで半角かどうかの種別を取得できます。
例えば文字列に半角を含むか否かをチェックする関数であれば以下のようになります。
func HasHalfWidth(strings string) bool { for _, s := range []rune(strings) { p := width.LookupRune(s) if p.Kind() != width.EastAsianFullwidth && p.Kind() != width.EastAsianWide { return true } } return false }
はまりどころ
上の例で、EastAsianFullwidthやEastAsianWideが出てきました。これはなんでしょうか?
width.Kindの定義を覗いてみると以下のようになっています。
// Kind indicates the type of width property as defined in http://unicode.org/reports/tr11/. type Kind int const ( // Neutral characters do not occur in legacy East Asian character sets. Neutral Kind = iota // EastAsianAmbiguous characters that can be sometimes wide and sometimes // narrow and require additional information not contained in the character // code to further resolve their width. EastAsianAmbiguous // EastAsianWide characters are wide in its usual form. They occur only in // the context of East Asian typography. These runes may have explicit // halfwidth counterparts. EastAsianWide // EastAsianNarrow characters are narrow in its usual form. They often have // fullwidth counterparts. EastAsianNarrow // Note: there exist Narrow runes that do not have fullwidth or wide // counterparts, despite what the definition says (e.g. U+27E6). // EastAsianFullwidth characters have a compatibility decompositions of type // wide that map to a narrow counterpart. EastAsianFullwidth // EastAsianHalfwidth characters have a compatibility decomposition of type // narrow that map to a wide or ambiguous counterpart, plus U+20A9 ₩ WON // SIGN. EastAsianHalfwidth // Note: there exist runes that have a halfwidth counterparts but that are // classified as Ambiguous, rather than wide (e.g. U+2190). )
これらはユニコードコンソーシアムによって標準化された東アジアの文字幅の定義にそって実装されています。
https://unicode.org/reports/tr11/
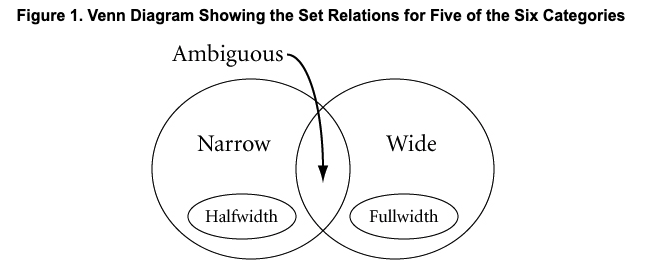
NarrowとWideに分類されますがどちらでもないAmbiguousが存在します。 見てみると、
Ambiguous width characters are all those characters that can occur as fullwidth characters in any of a number of East Asian legacy character encodings. They have a “resolved” width of either narrow or wide depending on the context of their use. If they are not used in the context of the specific legacy encoding to which they belong, their width resolves to narrow. Otherwise, it resolves to fullwidth or halfwidth. The term context as used here includes extra information such as explicit markup, knowledge of the source code page, font information, or language and script identification. For example: - Greek characters resolve to narrow when used with a standard Greek font, because there is no East Asian legacy context. - Private-use character codes and the replacement character have ambiguous width, because they may stand in for characters of any width. - Ambiguous quotation marks are generally resolved to wide when they enclose and are adjacent to a wide character, and to narrow otherwise. The East_Asian_Width property does not preserve canonical equivalence, because the base characters of canonical decompositions almost always have a different East_Asian_Width than the precomposed characters. East Asian Width is designed for use with legacy character sets so the property value is not designed to respect canonical equivalence.
文脈やフォントによってwidthが変化するものが存在するようです。
実際のバリデーションのユースケースでは文字範囲を絞ることの方が多いので、厳密なバリデーションを行う場合は、width判定を行う前段として文字範囲をチェックするか、正規表現等を用いた方が良いでしょう。
最後に
Kyashでは一緒に働いてくださるエンジニアを募集中です。 Fintechにご興味のある方是非是非選考のご応募待っております